Biopython: Tutorial and Cookbook
Python Tools for Computational Molecular Biology
by Jeff Chang, Brad Chapman, Iddo Friedberg, Thomas Hamelryck, Michiel de Hoon, Peter Cock, Tiago Antao, Eric Talevich, Bartek Wilczyński

DescriptionTable of ContentsDetailsHashtagsReport an issue
Thegoal of Biopython is to make it as easy as possible to use Python for bioinformatics by creating high-quality, reusable modules and classes.
Biopython features include parsers for various Bioinformatics file formats (BLAST, Clustalw, FASTA, Genbank,...), access to online services (NCBI, Expasy,...), interfaces to commonand not-so-common programs (Clustalw, DSSP, MSMS...), a standard sequence class, various clusteringmodules, a KD tree data structure etc. 
Book Description
The Biopython Project is an international association of developers tools for computational molecular biology. Python is an object oriented, interpreted,flexible language that is becoming increasingly popular for scientific computing. Python is easy to learn, hasa very clear syntax and can easily be extended with modules written in C, C++ or FORTRAN.Thegoal of Biopython is to make it as easy as possible to use Python for bioinformatics by creating high-quality, reusable modules and classes.
Biopython features include parsers for various Bioinformatics file formats (BLAST, Clustalw, FASTA, Genbank,...), access to online services (NCBI, Expasy,...), interfaces to commonand not-so-common programs (Clustalw, DSSP, MSMS...), a standard sequence class, various clusteringmodules, a KD tree data structure etc.
This open book is licensed under a Open Publication License (OPL). You can download Biopython: Tutorial and Cookbook ebook for free in PDF format (3.0 MB).
Table of Contents
Chapter 1
Introduction
Chapter 2
Quick Start - What can you do with Biopython?
Chapter 3
Sequence objects
Chapter 4
Sequence annotation objects
Chapter 5
Sequence Input/Output
Chapter 6
Multiple Sequence Alignment objects
Chapter 7
BLAST
Chapter 8
BLAST and other sequence search tools
Chapter 9
Accessing NCBI's Entrez databases
Chapter 10
Swiss-Prot and ExPASy
Chapter 11
Going 3D: The PDB module
Chapter 12
Bio.PopGen: Population genetics
Chapter 13
Phylogenetics with Bio.Phylo
Chapter 14
Sequence motif analysis using Bio.motifs
Chapter 15
Cluster analysis
Chapter 16
Supervised learning methods
Chapter 17
Graphics including GenomeDiagram
Chapter 18
KEGG
Chapter 19
Bio.phenotype: analyse phenotypic data
Chapter 20
Cookbook - Cool things to do with it
Chapter 21
The Biopython testing framework
Chapter 22
Advanced
Chapter 23
Where to go from here - contributing to Biopython
Book Details
Title
Biopython: Tutorial and Cookbook
Subject
Computer Science
Publisher
Self-publishing
Published
2020
Pages
360
Edition
1
Language
English
PDF Size
3.0 MB
License
Open Publication License
Related Books

The overall aim of this book, an outcome of the European FP7 FET Open NESS project, is to contribute to the ongoing effort to put the quantitative social sciences on a proper footing for the 21st century. A key focus is economics, and its implications on policy making, where the still dominant traditional approach increasingly struggles to capture ...

Optimizing HPC Applications with Intel Cluster Tools takes the reader on a tour of the fast-growing area of high performance computing and the optimization of hybrid programs. These programs typically combine distributed memory and shared memory programming models and use the Message Passing Interface (MPI) and OpenMP for multi-threading to achieve...

Online teaching can quickly become overwhelming. Finding ways to offer detailed and quality support, learning, and feedback, but through efficient and time-saving methods, will mean higher quality learning for less instructional time. For example, save all the course announcements, as they can be reused time and again. Create files of all tutorials...

The Raspberry Pi is loved the world over by educators and makers thanks to its tiny size and endless possibilities. Find out why it's loved and how to use it with the latest official Projects Book - we've managed to stuff the fifth edition with another 200 pages of inspiring projects, practical tutorials, and definitive reviews.
- Lear...
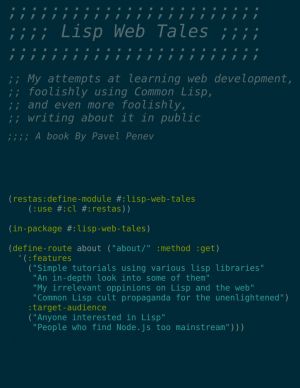
The book is a set of tutorials and examples. It uses the Common Lisp language and some of the libraries we'll be using for the examples and tutorials include:
- The hunchentoot web server
- The Restas web framework
- The SEXML library for outputting XML and HTML
- Closure-template for HTML templating
- Postmodern for PostgreSQL access, an...

Streamline software development with Jenkins, the popular Java-based open source tool that has revolutionized the way teams think about Continuous Integration (CI). This complete guide shows you how to automate your build, integration, release, and deployment processes with Jenkins - and demonstrates how CI can save you time, money, and many headac...